Mesh Side-Channel Attack
Introduction
In this blog, I will briefly introduce a research project done by our group which we have submitted to a top conference. You could find further details on our paper.
By accessing cachelines to make directed data flow, we could congest the router of Mesh Interconnect of server-grade CPU, where we could get a stable delay. If another program access the memory at the same time and the cachelines are transferred from the router we congested, we could observe a higher dealy. By recording all the delays, our attack is able to deduce the victim program’s secret information, for example, the private key of RSA. We attacked the Java program running on JVM, and captured the Square and multiply sequences.
Our attack contains the three parts of work.
- The reverse engineering of Mesh NOC topology.
- Implementing point-to-point mesh accessing and make the interconnect congested.
- Recording the logs and deduce the secrets.
Reverse Engineering
Take an example of Xeon 8260(our experiment environment), there are 28 tiles on the CPU chip, and each tile has core and uncore components. The CHA of uncore component is responsible to reply the LLC access from cores and manage the LLC on this tile.
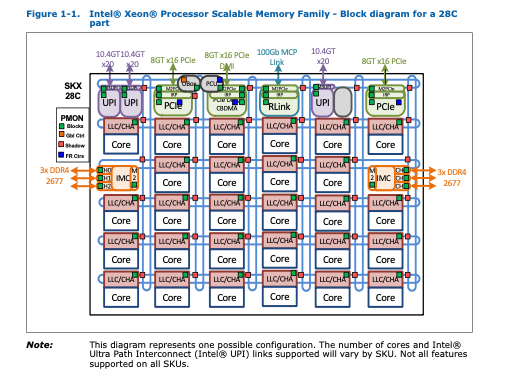 To make point-to-point congestion, we should learn the mapping relationships of tiles, CHAs, and cores.
Firstly, 4 tiles of 8260 were disabled after it produced. And we will confirm which 4 cores are disabled by reading msr register CAPID6. In our machine, bits 2, 3, 21, and 27 are 0, which means that these four tiles are disabled. As a result, the layout is as following:
To make point-to-point congestion, we should learn the mapping relationships of tiles, CHAs, and cores.
Firstly, 4 tiles of 8260 were disabled after it produced. And we will confirm which 4 cores are disabled by reading msr register CAPID6. In our machine, bits 2, 3, 21, and 27 are 0, which means that these four tiles are disabled. As a result, the layout is as following:
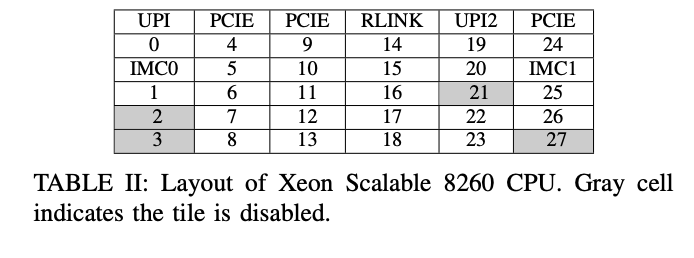
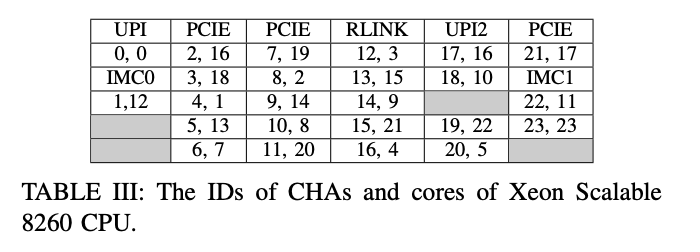
By the way, the ID of tiles and CHAs are growing from top to down and left to right. As a result, CHA 2 is in tile 4. In this way, we could map the CHA ID with tile ID for all CHAs.
We also need the relationships between core ID(core ID is the physical core ID in OS) and CHA ID. We found this information could be got by a PMU event - LCORE_PMA GV (Core Power Management Agent Global system state Value). Firstly, we bind a process to a core(ID=X), and do a lot of operations with that process(e.g. access a large volume of memory.) At the same time, we monitor the LCORE_PMA GV counter of every CHA. We could observe that the counter on one CHA(ID=Y) is higher than others. So we can confirm that core X and CHA Y lay on the same tile because the activities of core X could change the power management state of CHA Y. Repete the above procedure from core 0 to core 23, we could learn the mappings between core and CHA as the following picture shows.
Point to point mesh interconnect congestion
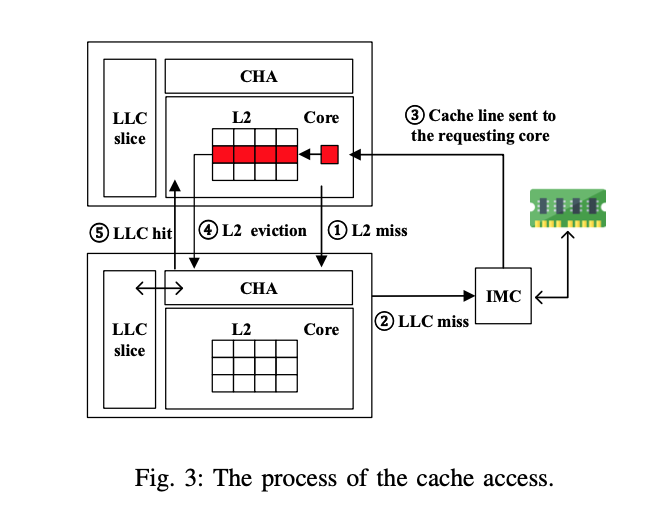 As the picture shows, LLC is non-inclusive by cores, while L1/L2 is inclusive by cores. So, a core on CPU could use access LLC slices from any tiles. LLC is managed by CHA on the tile, and a hash algorithm could determine the corresponding CHA ID which manages a specific Cacheline. By the way, the input of this hash algorithm is bit 6 to bit 64 of the physical memory.
As the picture shows, LLC is non-inclusive by cores, while L1/L2 is inclusive by cores. So, a core on CPU could use access LLC slices from any tiles. LLC is managed by CHA on the tile, and a hash algorithm could determine the corresponding CHA ID which manages a specific Cacheline. By the way, the input of this hash algorithm is bit 6 to bit 64 of the physical memory.

We devise an evict-based method L2-evict to make the memory access flow, which is similar to the concurrent work Lord of Ring. Suppose we want to congest the interconnect between core R and CHA T. Firstly, we will find an EV(eviction set) set. Cachelines in one EV set will be in a set of core R’s L2 cache and will be managed by CHA T. To find the EV set of a specific LLC slice, we use check_conflict and find_EV functons in Attack Directory. Such information could also be obtained by PMU events. And to get cachelines in one specific L2 cache set, we use bit 6-bit 15 of physical memory.
If we access the cachelines in the above EV set, cachelines will be evicted from L2 to LLC and then reload from LLC to L2 (The L2’s evict policy is pseudo-LRU). In our machine, an L2 set has 16 ways, and an LLC set has 11 ways. To avoid the situation that cachelines in LLC are evicted to memory which will introduce a higher delay, we will make half of bit 16 of EV’s cachelines to 0 and the other to 1. In this way, EV will be evicted to 2 LLC sets. According to our test, setting the number of cachelines in EV to 24 could maximize the congestion of the mesh interconnect.

Recording and Analysis
We will access 20 EVs and record the rdtscp timestamp once a time (in actuality, we access 10 EVs and each of them twice). By the gaps between rdtscp timestamps, we could infer the program’s secret information.
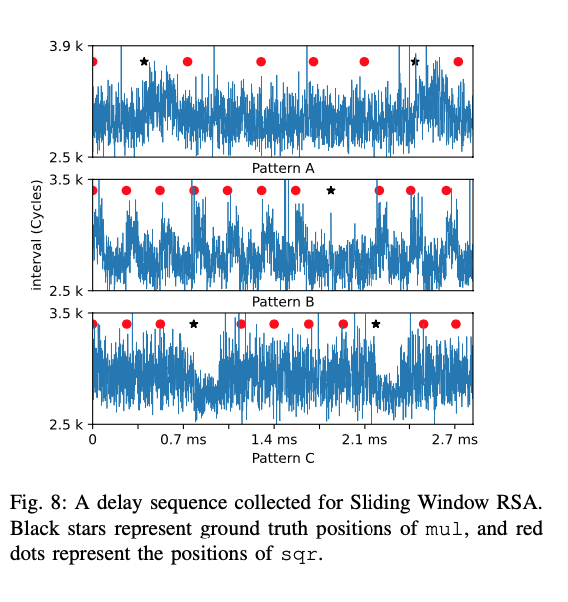
For example, when a Java program running on JVM is decrypting an RSA-encryped message with a private key, it will call the modPow() method of BigInteger package of JDK, which adopts a slide-window algorithm. And our attack is able to capture the square and Multiply sequences in the process of the slide-window algorithm. As the following picture shows, we could capture 3 kinds of memory access patterns. For instance, in pattern B we could observe square operations directly and then we could deduce the multiply operations by the gaps between the captured square operations. By applying a SRID algorithm, we could recover about 30% bits of the private keys.